

Dużo się dzieje w świecie AI
I o tym, co to oznacza dla biznesu


Nowe narzędzia i potwierdzone intuicje
Dzisiejszy mail będzie skupiony głównie na nowościach w świecie AI, bo sporo się ostatnio wydarzyło i warto na to spojrzeć z bliska.
OpenAI, wielomodalność, aplikacje, pamięć
Wczoraj wieczorem czasu polskiego OpenAI pokazał swój nowy natywnie wielomodalny model GPT-4o (o jak omni). Analiza obrazu dostępna była w GPT-4, więc co tak naprawdę się zmieniło? Wyjaśnię na przykładzie funkcji aplikacji mobilnej ChatGPT (którą lubię, a która nie jest zbyt często używana): konwersacji głosowej.
Do tej pory konwersacja głosowa z GPT-4 przez aplikację ChatGPT odbywała się w następujący sposób:
transkrypcja głosu na tekst przy pomocy modelu speech-to-text
wygenerowanie tekstowej odpowiedzi przez GPT-4
wygenerowanie głosu przez model text-to-speech
Te kroki powodowały duże opóźnienie w takiej konwersacji, sięgające minimum 5 sekund, zanim model zaczął odpowiadać po zadaniu pytania. Ponadto, nie było możliwości przerwania - co bywało uciążliwe kiedy nie skończyliście wypowiedzi a model już generował swoją. Taki dialog z podziałem na tury.
Model GPT-4o jest dużo szybszy, bo analizuje głos i generuje głos w jednym kroku, zamiast rozbijać proces na trzy kroki. Ponadto, można mu przerwać, bo analizuje głos użytkownika w trybie ciągłym, a nie w określonych momentach. To jest właśnie natywna wielomodalność - możliwość przyjmowania i generowania czegoś więcej niż tekst, bez kroków pośredniczących.
Model GPT-4o dostępny jest już dla wszystkich użytkowników, łącznie z tymi, którzy mają darmowe konto w serwisie ChatGPT. Funkcja czatu głosowego pojawi się za kilka tygodni, podobnie jak aplikacja na komputer (!).
Tak, tak, będzie można zainstalować ChatGPT na komputerze, żeby skorzystać z wielomodalnych możliwości. Aplikacja będzie w stanie monitorować ekran użytkownika (nie będzie konieczności robienia zrzutów ekranu i wklejania do okna przeglądarki). Możliwość dyskusji z AI na temat tego, co się widzi na ekranie to zupełnie nowa jakość, jeśli chodzi o doświadczenie użytkownika.
Ta funkcjonalność zostanie uzupełniona o pamięć, tj. model będzie się uczył preferencji użytkownika (wprowadzono to kilka tygodni temu w aplikacji przeglądarkowej, ale nie wszyscy mają jeszcze do tego dostęp).
Co to oznacza dla biznesu? Jeszcze niższy próg wejścia, jeśli chodzi o wspomaganie pracy i ogromny hałas, jak nagle wszyscy pracownicy zaczną rozmawiać z komputerem ;). A tak bardziej poważnie, to bardzo na tych rozwiązaniach skorzystają pracownicy “w niedoczasie”, dlatego, że mówienie jest szybsze niż pisanie. Bezpieczne tworzenie szkiców odpowiedzi na maile podczas jazdy samochodem, notatki głosowe, którymi w końcu da się sensownie zarządzać, konwersja nieuporządkowanych myśli do ustrukturyzowanego tekstu - to wszystko dziś jest możliwe, ale UX rozwiązań, które to oferują pozostawia wiele do życzenia (mówiąc wprost - korzystanie z tych narzędzi dzisiaj jest tak upierdliwe, że nie znam nikogo poza największymi fanami GenAI, kto by z nich regularnie korzystał). Już wkrótce się to zmieni.
Łyżka dziegciu: GPT-4o ma możliwość analizy emocji użytkownika. EU AI Act w kilku miejscach zabrania stosowania systemów analizy emocji. Nie wiem jak to zostanie rozwiązane, ale być może Europa nie dostanie dostępu do wersji głosowej, nawet jeśli regulacje jeszcze nie weszły w życie.
Znowu o “inżynierii” promptów
Jeśli już rozmawialiście ze mną nt. rozwiązań AI w biznesie, albo czytacie ten newsletter od dłuższego czasu, to doskonale wiecie, że “inżynierię promptów” uważam za umiejętność, której nie warto się uczyć, a sama obietnica “inżynierii” nie jest możliwa do spełnienia (instrukcje są niestabilne, trzeba je często poprawiać - to nie jest tak, że skoro działają dzisiaj, to za pół roku będą działać w taki sam sposób). Dużo efektywniej jest użyć samych modeli językowych do generowania instrukcji dla siebie samych.
To generowanie instrukcji dla siebie samych może przyjąć wiele różnych form, ale nie wszystkie dostępne są dla nie-programistów. Najprostsza wersja dostępna dla wszystkich to po prostu instrukcja dla modelu, takiego jak ChatGPT, w stylu “napisz instrukcję dla GPT, który…”. Anthropic chyba jako pierwszy (i podejrzewam, że nie jako ostatni) dołożył taką opcję do swojego narzędzia (to nie jest screenshot z Claude’a, tylko z Workbench’a) pt. “wygeneruj prompta”:

Dlaczego to ważne? Bo pokonuje barierę “spróbowałem raz GenAI i to nie działa”. Znam wiele osób, które trzeba było namawiać całymi miesiącami na spróbowanie ChatGPT jeszcze raz, zrażonych pierwszą interakcją, podczas której zadali pytanie w stylu “czy śruba miski olejowej w Focusie ma rozmiar 1/2 czy 3/4 cala?” i zniechęceni byli odpowiedzią (nawiasem mówiąc zwróćcie uwagę na liczbę błędów: nastawienie na to, że model wie wszystko, użycie jako bazy danych, brak wystarczającej liczby szczegółów w zapytaniu). Takie osoby, jak dostaną łatwą możliwość wygenerowania instrukcji, która działa, przestaną się zniechęcać tak szybko. Kolejne ułatwienie we wdrożeniu.
Czy ten pattern tworzenia instrukcji za użytkownika w jawny sposób (tak jak to proponuje Anthropic) się utrzyma, czy jednak ten krok zostanie schowany (jak próbuje to robić OpenAI, na przykład podczas używania DALL-E w ramach płatnej wersji ChatGPT), trudno powiedzieć. Ale “inżynieria promptów” zostanie raczej kompetencją głównie osób tworzących i optymalizujących narzędzia GenAI, a nie samych użytkowników.
Ceny sztucznej inteligencji idą w dół
OpenAI ściął ceny API (koszty per token, kiedy korzysta się z API, a nie subskrypcji ChatGPT Plus) - najnowszy model GPT-4o jest o połowę tańszy niż GPT-4. Optymalizacja kosztów obsługi GenAI nie wydaje się mieć końca, więc wojna cenowa będzie trwać.
Jeśli ograniczacie wdrożenia GenAI z powodu kosztów korzystania z modeli językowych, to warto moim zdaniem przemyśleć podejście, bo dziś te koszty wydają się nie do przeskoczenia, za pół roku mogą być tylko bolesne, a za rok, niezauważalne w ogólnym rozliczeniu.
Spójrzcie na wykres poniżej (źródło: https://artificialanalysis.ai/ ) - spójrzcie jaką presję cena API GPT-4o (i udostępnienie go za darmo za konsumentów) wywiera na oferty firm Anthropic, Google czy Mistral (wszystkie 3 są droższe, ostatnie dwa dużo słabsze).
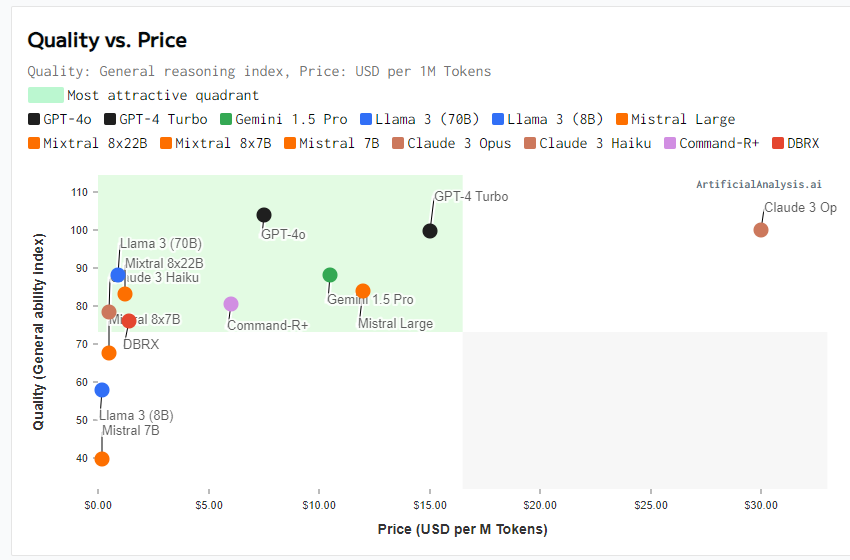
M.in. z tego powodu, nie mam rocznej subskrypcji na jakiekolwiek narzędzie AI i nikomu nie polecam wiązać się na rok z dowolnym dostawcą. Koszt zmiany dostawcy jest nikły, a jak pokazuje powyższy wykres, różnice cen mogą sięgać 10x za bardzo zbliżone kompetencje.
Warto odróżnić, czy wdrożenie w Twojej firmie idzie powoli (lub wcale) z powodów kompetencyjnych czy kosztowych. To drugie może nie być wkrótce problemem.